Cross Entropy and Log Likelihood
Ironing out some confusion I had about the relationship between cross entropy and negative log-likelihood.
I lately ironed out a little confusion I had about the correspondence between cross entropy and negative log-likelihood when using a neural network for multi-class classification. I'm writing this mostly so I have a handy reference in future.
Suppose we have a neural network for multi-class classification, and the final layer has a softmax activation function, i.e.,
$\hat{\mathbf{y}} = \sigma(\mathbf{z})$,
where
$\sigma(\mathbf{z})_j = \frac{\exp(z_j)}{\sum_{k=1}^{M}\exp(z_k)}$.
The vector $\hat{\boldsymbol{y}}$ is of length $M$ and can be interpreted as the probability of each of $M$ possible outcomes occuring, according to the model represented by the network.
The model is discriminative (or conditional), meaning that it models the dependence of the unobserved variable $y$ on the observed variable $\boldsymbol{x}$. The model is parameterised by the parameters of the network, $\boldsymbol{\theta}$. I.e., the network represents a conditional probability distribution $\mathrm{p}(y \mid \boldsymbol{x}, \boldsymbol{\theta})$.
Ignoring any issues with generalisation, suppose we want to choose the model (within the family of models the network architecture represents) that maximizes the likelihood of the observed data. I.e., we want to find the value of the parameters $\boldsymbol{\theta}$ that maximizes the likelihood of the data. We'll do this by something like stochastic gradient descent, using the negative log-likelihood as a cost function.
How do we compute the likelihood of the data? If we make a single observation, and we observe outcome $j$, then the likelihood is simply $\hat{y}_j$.
If we represent the actual observation as a vector $\boldsymbol{y}$ with one-hot encoding (i.e., the $j$th element is 1 and all other elements are 0 when we observe the $j$th outcome), then the likelihood of the same single observation can be represented as
$\prod_{j=1}^{M}\hat{y}_j ^ {y_j}$, since each term in the product except that corresponding to the observed value will be equal to 1.
The negative log likelihood is then
$-\sum_{j=1}^{M} y_j \log{\hat{y}_j}$.
Now, we know that the vector $\hat{\boldsymbol{y}}$ represents a discrete probability distribution over the possible values of the observation (according to our model). The vector $\boldsymbol{y}$ can also be interpreted as a probability distribution over the same space, that just happens to give all of its probability mass to a single outcome (i.e., the one that happened). We might call it the empirical distribution. Under this interpretation, the expression for the negative log likelihood above is also equal to a quantity known as the cross entropy.
Cross entropy
If a discrete random variable $X$ has the probability mass function $f(x)$, then the entropy of $X$ is
$\mathrm{H}(X) = \sum_{x}f(x)\log \frac{1}{f(x)} = -\sum_{x}f(x)\log f(x)$.
It is the expected number of bits needed to communicate the value taken by $X$ if we use the optimal coding scheme for the distribution.
Imagine arranging the possible values of $X$ on a line, with each outcome occupying an area proportional to its probability.
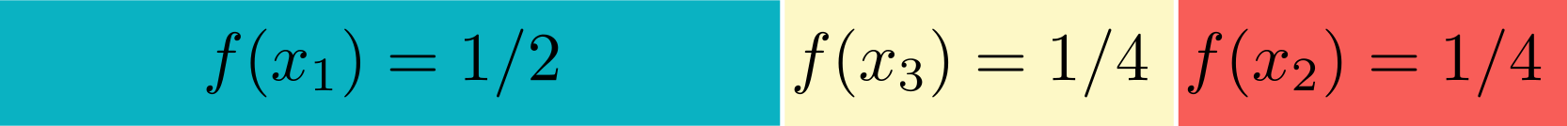
If we take the base-2 logarithm, you can think of $\log \frac{1}{f(x)}$ as being the number of yes/no questions you need to ask (if you ask the right questions) to narrow yourself down to the region of the line containing the outcome $x$. For example, using the above probability space we would first ask "Is the outcome in the first half of the line?", so would only ask one question to determine that the outcome was $x_1$. If the outcome is not $x_1$ then we have to ask a second question. The entropy is just the expected number of yes/no questions you'll need to ask; it's the sum of the number of questions for each possible outcome, each weighted by the probability of that outcome. (We don't literally ask questions about where we are in the probability line. Instead, we assign strings of bits to possible outcomes. So in the above example, we assign the string '0' to the outcome $x_1$, '10' to $x_2$, and '11' to $x_3$.)
The key in the above paragraph was the phrase "if you ask the right questions".
If we choose our series of yes/no questions to minimize the average number of questions we'd have to ask if the probability mass function over the outcomes was $f(x)$, but in reality the probability mass function is $g(x)$,

then we're going to have to ask more yes/no questions to determine the outcome than if we used the optimal series of questions for $g(x)$. It's like if you'd played the game '20 questions' with your friend Alice so many times that you've got to learn the kind of objects she chooses, and tailored the sequence of questions to her. When you come to play the game with Bob, the questions aren't quite a perfect fit, and so you have to ask more questions on average.
The expression for the cross entropy is
$\mathrm{H}(g, f) = \sum_{x}g(x)\log \frac{1}{f(x)} = -\sum_{x}g(x)\log f(x)$.
(I don't really like the standard notation here. $\mathrm{H}(X, Y)$, where $X$ and $Y$ are random variables, is taken to be the joint entropy of $X$ and $Y$, and $\mathrm{H}(f, g)$, where $f$ and $g$ are probability mass functions or probability density functions over the same space of events is taken to be the cross entropy of $f$ and $g$.)
One important thing to note is that $H(p, q) \neq H(q, p)$. So going back to our example of using the cross entropy as a per-example loss function, how do we remember which of the distributions takes which role? I.e., how do we remember, without re-deriving the thing from the negative log likelihood, whether we should we computing
$-\sum_{j=1}^{M} y_j \log{\hat{y}_j}$
or
$-\sum_{j=1}^{M} \hat{y}_j \log{y_j}$.
The way I remember it is using the intuition from above. In the expression for cross entropy, the distribution that we take the element-wise logarithm of is the one that we used to generate our coding scheme, i.e., it is the distribution that we think the data follows. We can remember this by remembering the idea that the base-2 log of the (inverse) probability for each possible outcome measures the number of yes/no questions we have to ask (each time bisecting the probability space) in order to determine that that outcome occurred. To calculate the average number of questions we have to ask, we just weight each number by the true probability of each outcome. Clearly $\hat{\boldsymbol{y}}$ represents the distribution that the network/model believes the data follows, and $\boldsymbol{y}$ is the actual data, and so is the true distribution.
K-L divergence
The Kullback-Leibler (K-L) divergence is the number of additional bits, on average, needed to encode an outcome distributed as $g(x)$ if we use the optimal encoding for $f(x)$. Using the above definitions for cross entropy and entropy we see that the K-L divergence is
$\mathrm{D}_{KL}(g\mid \mid f) = \mathrm{H}(g, f) - \mathrm{H}(g) = -(\sum_{x}g(x)\log f(x)-\sum_{x}g(x)\log g(x))$.
The K-L divergence is often described as a measure of the distance between distributions, and so the K-L divergence between the model and the data might seem like a more natural loss function than the cross-entropy.
In our network learning problem, the K-L divergence is
$-(\sum_{j=1}^{M} y_j \log{\hat{y}_j} - \sum_{j=1}^{M} y_j \log{y_j})$.
What if we were to use the K-L divergence as the loss function? We can see that the $\sum_{j=1}^{M} y_j \log{y_j}$ term depends only on the (fixed) data, not on the likelihood $\hat{\boldsymbol{y}}$, and so not on the parameters of the model $\boldsymbol{\theta}$. In other words, the value of $\boldsymbol{\theta}$ that minimizes the Kullback-Leibler divergence is the same value that minimizes the cross entropy and the negative log likelihood.
Multiple observations
If we have $N$ independently sampled examples from a training data set, the joint likelihood of the data is just the product of the likelihoods of the individual examples. The joint likelihood is
$\prod_{i=1}^{N}\prod_{j=1}^{M}{\hat{y}_{j}^{(i)}} ^ {y_{j}^{(i)}}$,
where $y_j^{(i)}$ is the target or outcome of the $i$th example, and $\hat{y}_j^{(i)}$ is the likelihood of that outcome according to the model.
The negative log likelihood is
$-\sum_{i=1}^{N}\sum_{j=1}^{M} y_j^{(i)} \log{\hat{y}_j^{(i)}}$.
One source of confusion for me is that I read in a few places "the negative log likelihood is the same as the cross entropy" without it having been specified whether they are talking about a per-example loss function or a batch loss function over a number of examples. As we saw above, the per-example negative log likelihood can indeed be interpreted as cross entropy. However, the negative log likelihood of a batch of data (which is just the sum of the negative log likelihoods of the individual examples) seems to me to be not a cross entropy, but a sum of cross entropies each based on a different model distribution (since the model is conditional on a different $\boldsymbol{x}^{(i)}$ for each $i$).
Edit (19/05/17): I think I was wrong that the expression above isn't a cross entropy; it's the cross entropy between the distribution over the vector of outcomes for the batch of data and the probability distribution over the vector of outcomes given by our model, i.e., $\mathrm{p}(\boldsymbol{y}\mid \boldsymbol{X}, \boldsymbol{\theta})$, with each distribution being conditional on the batch of observed values $\boldsymbol{X}$.